
Extending the git message conventions to prevent losing knowledge
Measures against losing knowledge due to AI

I’m sure you are familiar with commit messages that look like:
feat: added email notification on product shippedchore: upgraded library versionfix: JSON parser for DTO
A common value proposition from AI vendors is to delegate the commit message to AI.
It is useful, but generating a commit message doesn’t provide much value.
A good commit needs to help our teammates (and our future selves) to understand what changed and why.
And, a common thing that happens nowadays is that a lot of code is AI generated. I want to understand if the code that’s there has been written by you, which will have a higher chance that you will remember certain decisions you made, or it has been delegated to AI, which means that you might not member all the changes introduced.
What’s missing in the commits is this critical information.
That’s why I started adding some contextual information to my commit messages.
ai-{feat/chore/fix/docs}: <description>
Following the conventionalcommits.org specification, I started adding the suffix `ai-` to my commit messages to indicate that the commit contains code generated by AI.
Providing this context to our future selves will be key to understand how we are changing code.
ai-feat: added email notification on product shippedai-chore: upgraded library versionai-fix: JSON parser for DTO
Losing knowledge with LLMs
If you have been in the industry for a while, you know that knowledge is a headache for any company.
That’s why pair programming, mob programming, technical huddles, Architectural Decision Records, documentation, and so on have been adopted by more and more companies.
Because we learned the cost of losing knowledge.
And with AI, we are losing knowledge and know-how faster than ever. See Your Brain on ChatGPT: Accumulation of Cognitive Debt when Using an AI Assistant for Essay Writing Task paper.
If we aren’t pairing as much, and we delegate a lot to LLMs, what can we do to minimize the knowledge lost?
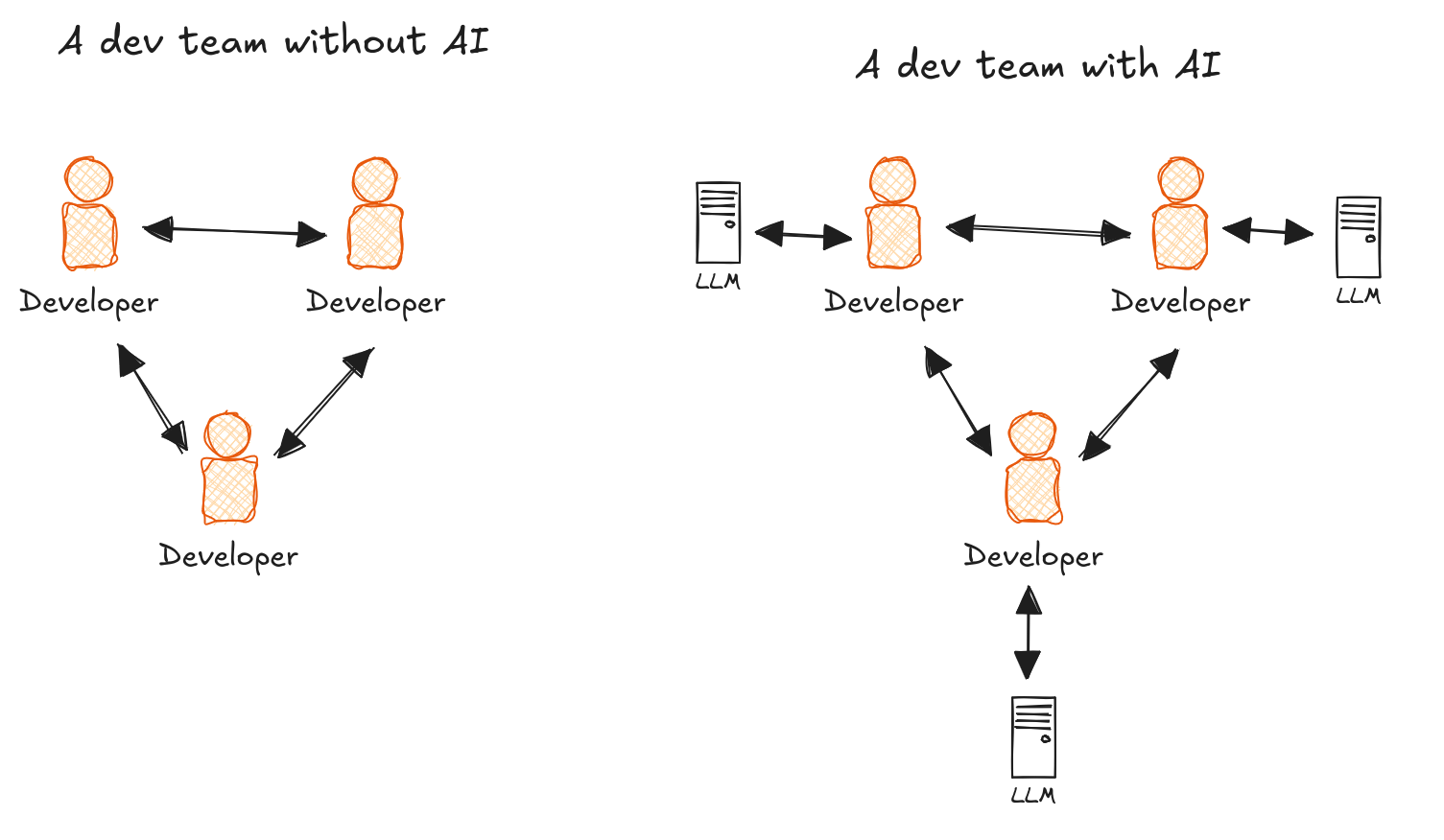
The problem is even worse as you think about it.
LLM providers harvesting business knowledge
Each developer is sending a lot of information to LLM providers. They are able to identify patterns not only cross your company, but cross competitors, and industries.
We are making our LLM providers to sense all the industry for a fraction of what it costs you to learn about it, and they will be able to out innovate us.
The need for self-hosted open models will become more and more obvious.
Each developer deviating about a common shared domain model as the LLMs introduces more local bias
Any person with a DDD background understand the importance of the Ubiquitous Language, and that all the people understand the meaning of each concept.
I’m seeing an increased problematic as we use more LLMs. Because of how many variables there are when we develop.
Imagine how fast we start losing the shared domain model when:
Using different LLM models: Each model has its own training set, its own definitions, and its own bias.
Each conversation with the LLM adds more context to the specific memory. But developers don’t share their chat memory between them. Creating bias, and re-work when different developers work on the same parts of the code.
Because it is easier to talk to an LLM (and we are disincentivizing the collaboration with product, design, and business that took us that long to build the culture of), our shared mental model will become worse and worse over time.
Creating more knowledge silos than before.
We need to be careful when leveraging the LLMs because they are trained on what’s known. And innovation isn’t about what’s know, but about unexplored space.
Using DDD terms, LLMs help us a lot on supporting subdomains. The core domains, those that are about the unknown, the hard stuff, why users buy you and not the others, that’s the hard part.
LLMs won’t fix those, but good cross-team collaboration will.
If an LLM can answer about it, it’s not core by definition.
Keeping the AI conversations within the Git history
commit 7457ef3dd201d0702c0f82e6e703b53f87db770e
Author: Aleix Morgadas <hello@aleixmorgadas.dev>
Date: Thu Aug 7 13:32:42 2025 +0200
ai-feat: <description>
# Prompt
<Prompt that triggered the change>
# Outcome
<Copilot, Agent, whatever chat that caused the changes>
# Meta
model: sonnet-4
mcp:I started adding all the information produced by AI as part of the Git History as a countermeasure to losing knowledge in the mid to long term.
That’s the only countermeasure I found that can help us to not lose all the knowledge it took us that long to gain.
I just copy the prompt and the outcome of the AI chat that explains the changes, and which model/MCPs have been used.
Here is an example with Cline Code Extension.
This way, by the time we start adding the right capabilities, we store as much of the information within our Git History. So that, by the time we want to start experimenting with all this information, and business knowledge, we have the data already in our systems.
Interesting that we started collecting all data from customers that we didn’t need as a company during the “Big data” hype, and we kind of forget some of those learnings.
Some examples would be:
Learning from each other’s prompts.
Knowing the decisions made with the AI and the developer that lead into the changes.