
Going to production killed fast flow. Understanding how company "culture" materializes on unaligned team dynamics
Fintech Engineering Strategy. Post V

The Fintech post series aims to share my personal experience as an engineer manager and later on as head of engineering, which were the challenges, the decisions, and the good and bad outcomes they had. The content has been adapted to keep the decisions without disclosing internal information.
Fintech Engineering Strategy Post Series
Post II. Building a product vision, and a team, and replacing Ktor with Spring Boot incrementally.
Post V. Going to production killed fast flow. Understanding how company culture materializes on unaligned team dynamics. [This post]
Post VI. Reducing the chaos before addressing the complex socio-technical system
On the previous post IV, I introduced that we 1) created a core team at tribe level 2) re-purposed the team to be a platform team.

But why did we re-purposed the team to be a platform team? In which context did it happen?
Context
We simplified the architecture, implemented the feedback and insights found by the beta customers. We released the MVP. 🙌
We reached a good team maturity at the same time the B2B2C product started to gain traction. The past decisions on focusing on this product to have a faster feedback loop started to pay-off.
The product value proposition was to help companies attract and retain talent by offering a better employee experience.
We onboarded few clients per month, which could mean between hundreds to thousands on employees. And with thousands of users per month, you start to see the system weaknesses. For the technical aspect, you see the service to start failing given several concurrent users. For the product/design aspect, you start seeing customers being unable to accomplish their main use case.
Customer tickets started to pile-up, developers were supporting the product constantly, and several manual processes that before weren’t painful, now was blocking all the fast flow.
Customer success team and Operations team were under pressure to resolve tickets to gain the customers trust and make sure they don’t churn. They hadn’t the right tools to make it happen, so they mainly created tickets for the Development Team to fix manually.
If the product-tech team is busy solving production issues, we weren’t improving the system. We weren’t able to escape the dynamics we created.
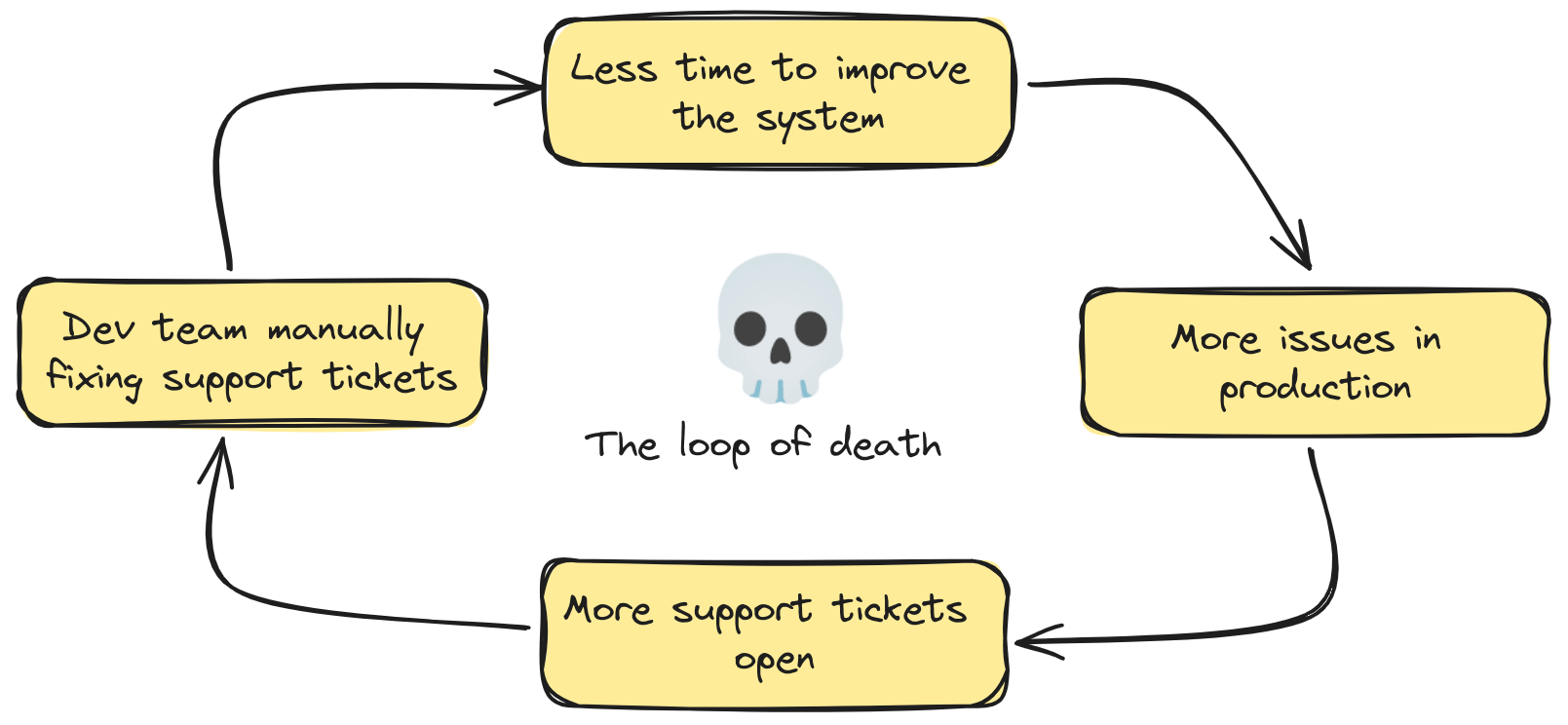
You know this virtuous cycle that deteriorates everything, architecture, code, team morale, customer trust, … which requires a bold decision to stop it.
In this post, which it needs to be spitted in multiple parts, I will go in depth on:
Understanding how the socio-technical system produced this result.
How leadership affected the whole team dynamics and how we had to change the whole tribe culture.
How using Team Topologies principles with Inverse Conway Maneuver while constantly measuring Team Cognitive Load helped us make sensible decisions.
Starting the change from the people and then though tech.
Understanding the technical landscape with Wardley Mapping and Domain Driven Design with Strategic Patterns.
Why the microservices failed and why the current approach didn’t work.
Directly challenge the company operating model on how it designed and decided the teams responsibilities.
Two teams discontinued and one team become a Platform Team.
I’m sharing with you a six month journey on how we changed completely a tribe from low performing to high performing and be a reference within the organization.
I hope you enjoy this in depth engineering strategy at multiple levels as much as I did working with my peers making it a reality.
Start sensing the grouping instead only the team
I shared between the Post I and IV different strategies that worked at team level because it was the high-stake challenge for the organization and required my full attention.
You can see how I kept involved at team level in the next diagram. I was able to sense problems at tribe level but I decided to ignore them to focus on the high-stake problem first.
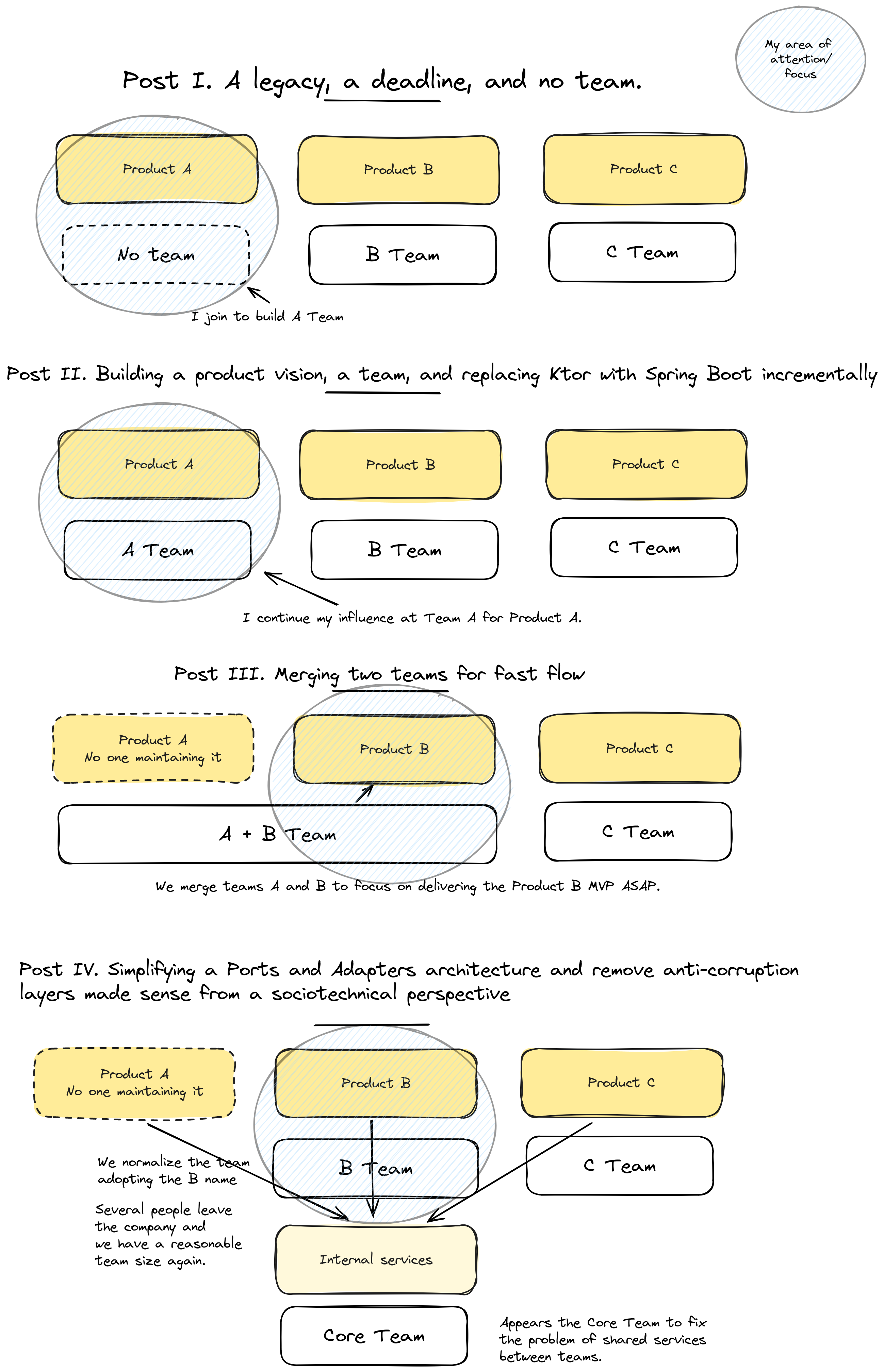
I don’t know if you remember, but I joined as Engineer Manager, but my attention was fully at team level. I had to start moving into tribe level challenges, and we were facing another fire 🔥 at team level.
With this peace and dynamic we wouldn’t move into a more stable context. We will move from fire to fire, creating an environment that’s tiring and burns out people.
The day to day was chaotic. We have production incidents due to systems being down with several customer tickets due to the system not being available.
At some point, I had to decide to lead things be on fire so we could make the improvements we all needed.

The good thing is that we had already some experience as a team working together, I was exposed enough to the company complexities, and I asked the team to sustain the situation while I had to focus on identifying the root cause. The team was mature enough that they didn’t depend on me on that chaotic and stresful situation.
So, I started sensing what was happening at tribe level.
There was something that seemed off. It looked like teams had problems, not the organization. The attention focused at team level, like the problem was there and so was the solution.
My helping with those fires and fixing them didn’t help. I was part of creating the hero culture. Those people that jump from fire into fire, and get good recognition for it. Who doesn’t like to be recognized to help on the hard moments?
That’s not a sustainable job. I started to think differently about the situation.
What if the teams were signaling deeper organization/company problems? If only one team underperforms is a team problem, if multiple teams underperform, it is an organization problem materialized at team level.
See your teams problems as signals to identify a deeper organizational problems. The team isn’t the problem but a organization’s mirror of why things work or doesn’t work.
I was to identify that each team had a different problem at first, but they seemed to follow a pattern.
Teams without products in production.
They need several months to release a product.Teams with products in production.
They cannot iterate the product and stabilize it because of the operability is high and there is more need to keep adding functionality.
There was something happening again with hand-offs, like I shared in the Merging two teams for fast flow post.

And then, all the sudden another team appeared! Why? When? How? WHAT!?
I started to host calls with every team leader within the tribe and people that depended on us, like Operations teams.
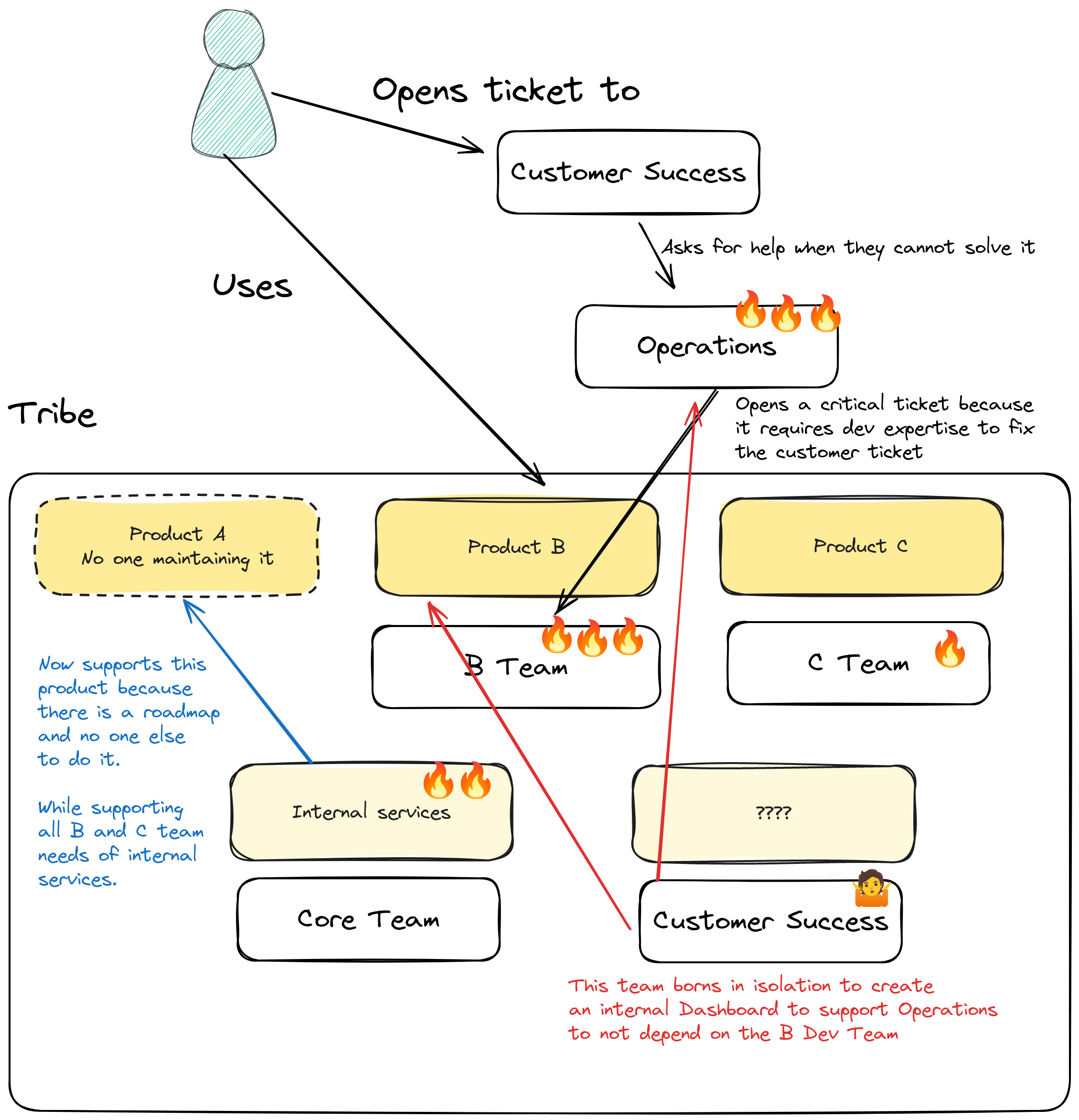
I discovered interesting things:
Core team was supporting the Product A development because no one else was doing it while teams B and C needed internal systems improvements that were blocking them.
Product B was using several of the internal services, some of which were unstable and their failures impacted the customer.
Supporting the customer happened outside the tribe responsibilities.
Product teams were seen still as feature factory outside the tribe (and probably within the tribe too…). Customer Success and Operations teams had the responsibility of providing a good customer experience and closing tickets as fast as possible.
They didn’t have the tooling to be autonomous, so they had to open tickets to the next layer until a developer was able to access the logs, the database, and call the right APIs in the right order to fix the customer problem.
This happens when you have a non-resilient distributed monolith BTW.
Because the responsibility was for the Operations division, they had the authority to create teams to support better the customers, so, they didn’t have to ask anyone to add a new team to our tribe with one objective. Help the other Operations teams to do their job faster.
BUT, how will they create a dashboard? They don’t have business nor development context. Will they integrate with our APIs that aren’t ready to make that? Will we have another user to support now? Why creating another handover instead of ourselves creating the Dashboard directly? Which we already started… Will they just add code to our repository?
At the beginning I remove handovers between internal teams. We created a team to deliver E2E, but it looks like the organization didn’t understand the same for supporting the customer. That was another team responsibility, you focus on delivering new things.
I naively expected to find an easier answer of what I needed to fix, but no, it was a complex human problem that materialized on the messy architecture we had.
I was seeing Conway’s Law in front of me, and the problematic resided outside the tribe.
I had to involve VP level people to understand better what was going on while the team in a chaotic situation, which they wouldn’t be able to sustain for too long.
So, we had to do two things:
Understand the whole complex context to start betting on how to improve the situation.
Just act to move away from the chaotic situation.
Following the Cynefin framework, we could say that we were in the next situation:
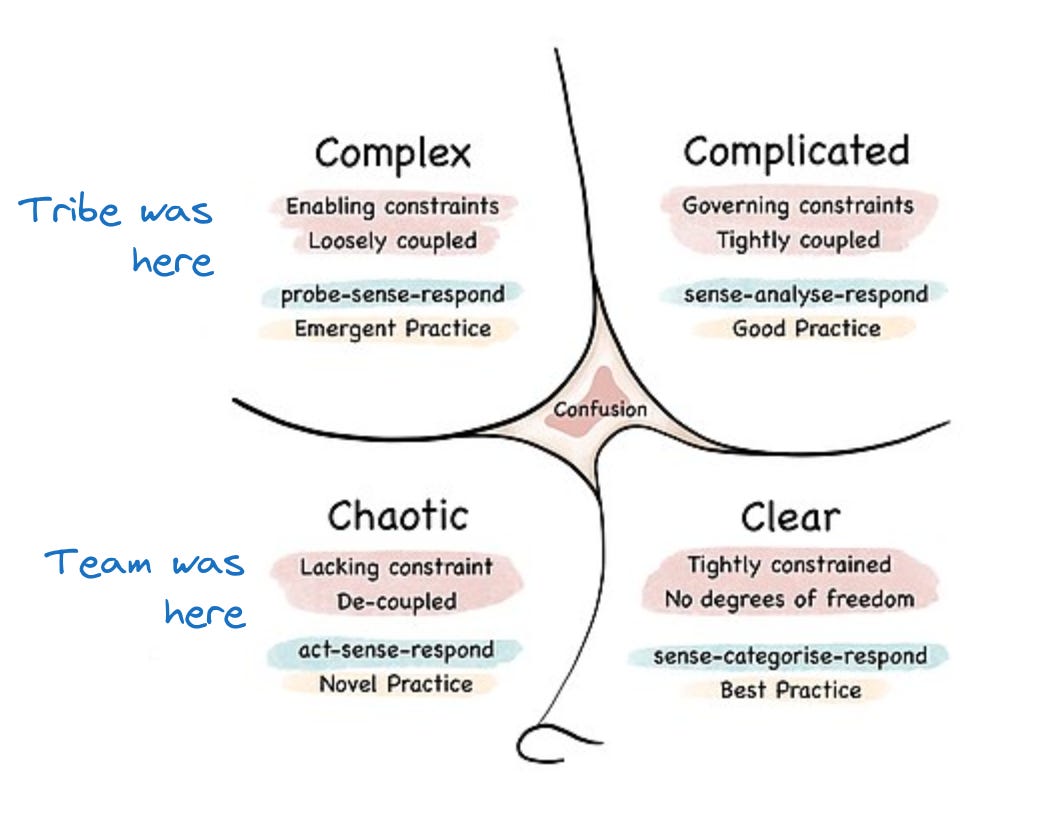
So… what to do?

Let’s do both starting by reducing the chaos 😄

In the next post I will share the tactical actions we did to reduce the chaos, and how we let things be on fire for a long while.