
Simplifying a Ports and Adapters architecture and remove anti-corruption layers made sense from a sociotechnical perspective
Fintech Engineering Strategy. Post IV

The Fintech post series aims to share my personal experience as an engineer manager and later on as head of engineering, which were the challenges, the decisions, and the good and bad outcomes they had. The content has been adapted to keep the decisions without disclosing internal information.
Fintech Engineering Strategy Post Series
Post II. Building a product vision, and a team, and replacing Ktor with Spring Boot incrementally.
Post IV. Simplifying a Ports and Adapters architecture and remove anti-corruption layers made sense from a sociotechnical perspective. [This post]
Post VI. Reducing the chaos before addressing the complex socio-technical system
I’m concerned about the amount of misunderstood ports and adapters architectures (from now on P&A arch.) out there, more specifically on the decision making process behind them.
The intention with this post is to give you tools and arguments to decide properly which architectural choices do you have and, instead, opt for an evolutionary approach when needed.
Architectural choices are sociotechnical systems decisions.
I briefly introduced the decision we took of replacing Ktor by Spring Boot in this post, yet, I think I could go more into the details and nuances of the decision.

If you want the short version of the full post, you can check this Tweeter thread.
In the thread I say replacing ports and adapters in favour of MVC+S. Indeed, I would say that what we did was a very thin ports&adapters where the ports and adapters were the ones that Spring Boot provides out of the box with spring-boot-web.
The thing is that a ports and adapters leveraging Spring Boot defaults looks like an MVC+Service, or 3'-layered architecture with an Application Service.
TLDR;
Ports and Adapters architecture isn’t a best practice nor a sign of quality by itself. Indeed, it can even show a poor situational awareness and imply a high accidental complexity and incurred cost to the business.
This is due to it is misunderstood and each implementation is different. The possibility of introducing accidental complexity is high due to it relies a lot on the developer criteria. And we have the tendency to complicate things, right?
If an architecture rely on the developers to keep it simple, it will tend to get complicated rather than the oposite.
I don’t mean that we shouldn’t write sustainable code with a good test base and good practices like observability. I mean that applying all the “popular best practices” without understanding how they apply to our context is a receipt for failure. Applying patterns without the situational awareness shows a lack of seniority or a desire for a CV oriented career.
Disclaimer: I did that mistake, and I took a long time to realize that the business is who keeps paying the consequences.
Learning them and applying specifically for the context at hand is what matters.

Today, I’m explaining you why we made some contra-intuitive decisions such as:
Migrating from ports and adapters full decoupled from the framework to ports and adapters coupled to spring boot.
Moving from Ktor and Exposed to Spring Boot.
Moving from anti-corruption layers to decouple from external systems to conformist (accepting the upstream model).
Coupling to Spring Boot and to upstream systems.
Introduce a Platform as a Product in the tribe lead by a Platform Team.
Which helped us to achieve stuff like:
Removing +1.000 LoC cross multiple services.
Removing several cross layers duplicated tests.
Reduce the cycle time and improved the lead time for features.
Improve the reliability of the systems.
Reduce the cognitive load of teams
Improve the onboarding time from 4-5 months when people felt productive to less than two months.
As side-effect, we made decisions based on the learnings we had that impacted the performance review, the career leader definition and the hiring process. In specific, it affected the senior+ developers job expectations. I’m also explaining why and what we did here.
The context

We just merged two teams, and we started to gain team momentum. People were doing pairing, started to know each other, and we were progressing from forming to storming based on Tuckman's model.
When things start to become less chaotic at human level, you can slow things down to understand the technical part.
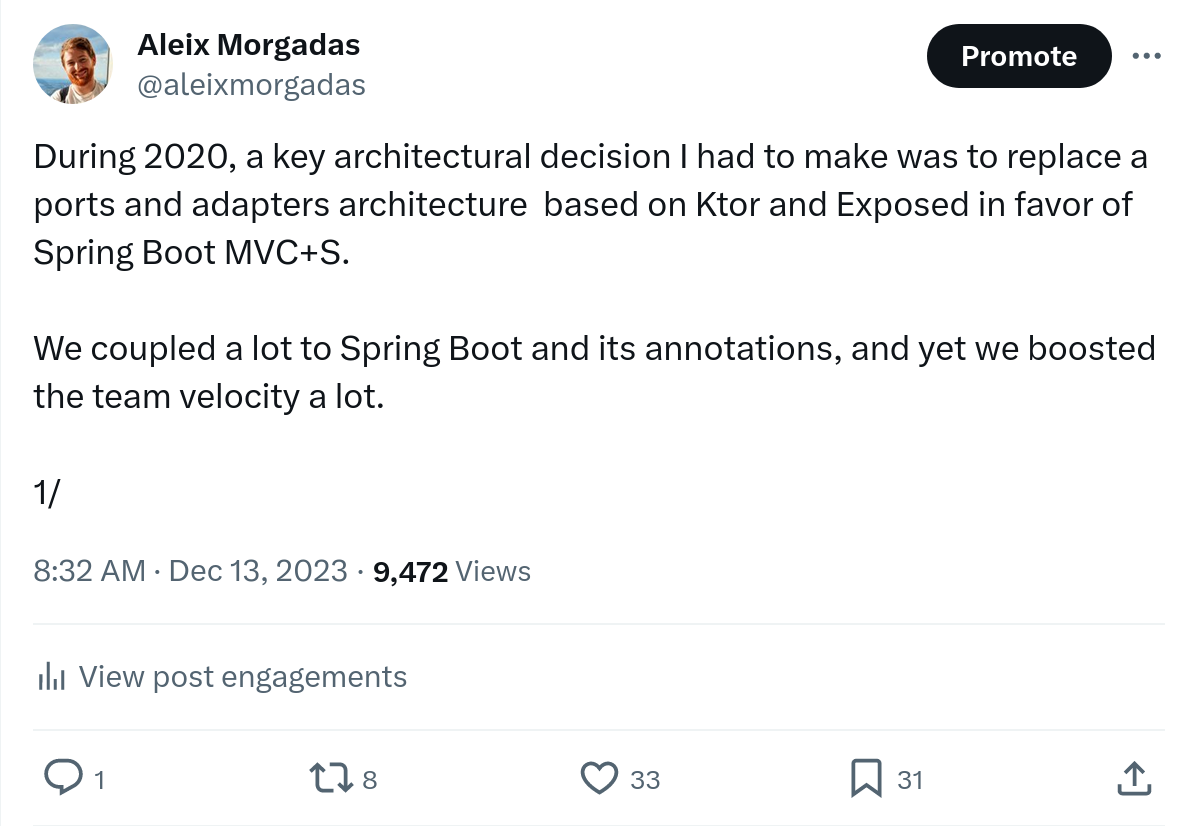
At tribe level, we had an architecture like this:

Warning: Notice that the diagram now it changed compared with the 2nd post series. A new team was created to handle the shared services. This is team was named core team. Later I share why the name core was bad, and why the approach had a good intentions yet was a bad implementation and why evolving into platform made sense.
If we look at each service, the architecture was ports and adapters. If we make a diagram to show the size of each layer, it would look like this:

We can notice a couple of things:
Services have few domain logic.
Services have a lot of network logic.
Domain logic poor-network rich logic service. And it made sense, we chosen an off-the-shelf solution that would handle a huge part of our business logic as it wasn’t a business differentiation but needed to run our business. So, we were calling a lot those external systems to handle the majority of use cases.
Two main questions raised:
Why ports and adapters if we mainly pass payloads around and we have very specific business logic?
The product complexity isn’t that high. It looks like an “state machine” plus smart component that connects specific.
But we are connecting to a lot of other systems that we don’t know if they will change the API or something. So, we want to protect ourselves from future changes regardless of the system. We apply this to all systems we integrate with.
Why that many ACL? From what we are protecting from?
When a team requires a change on the shared services owned by core team, it impacts all the other teams and we need to protect ourselves from those unanticipated changes. That gives us as a team the possibility to be autonomous to change things without breaking the others systems.
Each time we change a property in a system, we need to update the ACL of other systems we control. Usually, a change on one shared service, implies a change at least to two more services, ours and the BFF (backend for frontend), which we also did with Ktor and Ports and Adapters.
The conversation started at architectural level, but the problem wasn’t there. Focusing on the technology ignoring the human aspect of the problem would let us on the wrong direction.
The architecture and approach was a reflect of how the organization introduced change, who made decisions, and different incentives mechanisms.
In order to understand what was causing the outcome, I focused on the people.
I used:
Context Mapping from Domain-Driven Design strategic patterns.
Core domain charts to understand the domain complexity.
Job expectations.
Understanding
Context mapping
Context mapping helps you understand the teams relationship and how flow is handled by teams.
I went to the engineers and asked how they saw the context mapping of the tribe services from a teams perspective.
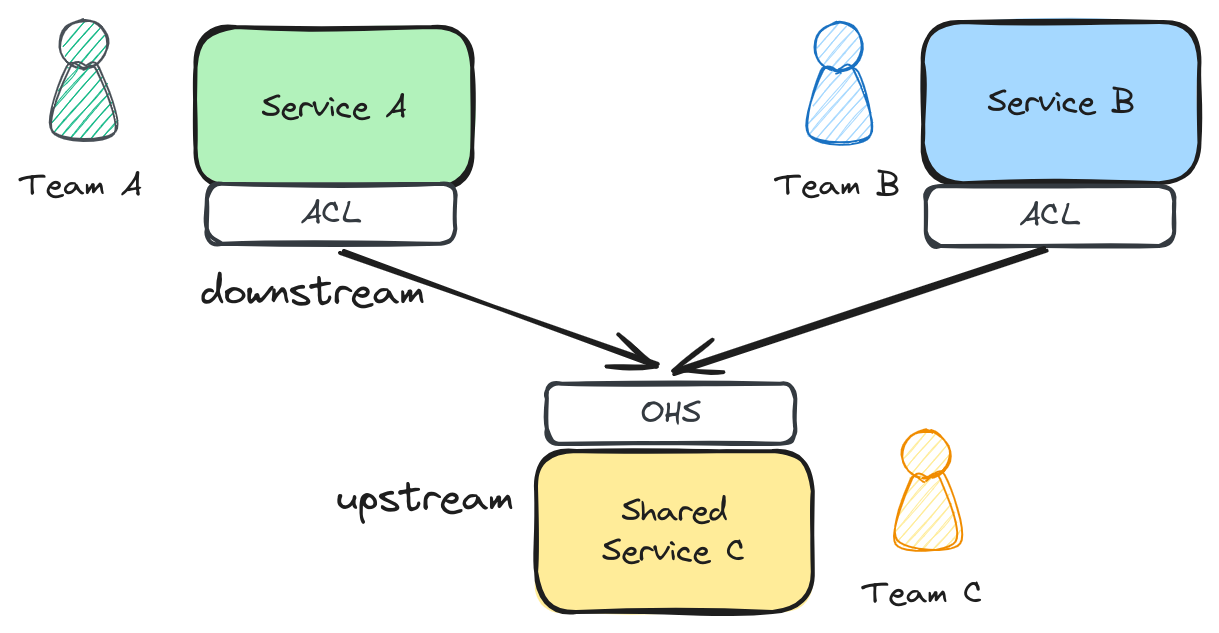
The diagram makes sense my itself, but misses how change happens.
Aleix: How do you introduce change to those shared services?
Team: We share the blocking dependency and then our tech lead and core team tech lead negotiates when the change can be ready.
Aleix: How often do you need to request changes?
Team: Weekly, we strongly depend on them due to they being the door to our external partner systems.
Aleix: And they are unable to make the change?
Team: We just do it ourselves if we need it with high priority.
Let’s update the diagram with the new findings.
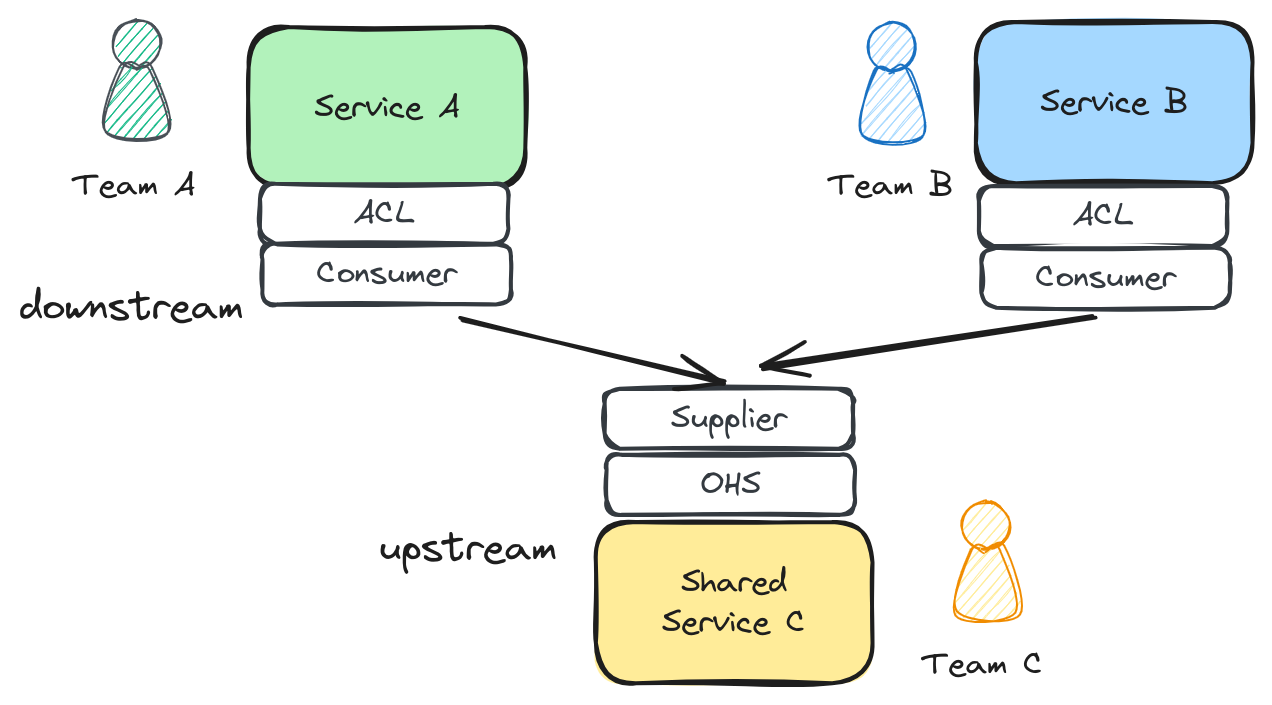
We had a consumer-supplier relationship with the customer facing teams and the internal core team. Which means that the team C was having problems keeping up with the high demands of customer facing teams that caused them to not be able to improve the services.
I added the one box per team, remember that the core team had more than 5 services they owned that customer facing teams consumed and required changes to keep building their products.
Analysis
When you have a lot of anti-corruption layers and consumer-supplier team relationships it can be an smell that something is off.
As engineers, our main tool to protect from change is code. It can manifest as anti-corruption layers for example. Yet, the key problem of why they needed to protect themselves from constant changes is how change happened in the organization.
It happened at product manager and tech lead level.
This situation made each group of people to make their best to keep the delivery forward but making the whole organization slower.
Core domain charts
When people is measured by their impact, they will work on the core business domains.

Aleix: Let’s list our domains and services that we own as a tribe.
Team: Sure, here it is!
Aleix: Thank you! Let’s introduce the DDD subdomain types.

Aleix: How would you define your services based on those types?
Team: (summarized) What we do is core, what we don’t do isn’t core.
There is a lot of truth behind those words.
If your performance review is based on your business impact, you need to work on core stuff. Otherwise, how do you demonstrate your contribution to the business success?
Team: We already did this exercise, we already applied DDD to our services.
Aleix: Applied DDD to the services? Could you elaborate that please?
Team: Yes. Our core services need to handle a lot of complexity, and we adopted a ports and adapters architecture to allow fast iteration and high quality software. That’s why we have created a microservice per domain. They focus to do their domain responsibility super well, and then we allow others to interact with each one so that we reuse domain logic.
This is an argument that I heard too often. It looks OK at first, but indeed, from that argument to the reality there is a full world in the middle.
Let’s break the argument and analyse it separately to uncover the consequences.
Our core services need to handle a lot of complexity.
There are no core services, there are core subdomains that might or might not be a service. They can be an application, a module within the monolith, an actual service.
I wouldn’t expect a product that’s forming to handle a huge amount of complexity at first. I assume they need to fulfill two properties first before you start sensing the high complexity you are promised for:
You should validate that the domain is core working with product and business to verify it is a competitive advantage for your organization. In order to verify that’s a competitive advantage, you need to accept a lot of rapid iteration (change often), and when you start sensing the direction, you start seeing how the complexity materializes.
If your understanding of a core domain is complexity, you will force it to be there by adding unnecessary complexity. Some people adds CQRS, ES, and P&A arch. because they read on a blog post that’s the best way to handle complexity.
We adopted a ports and adapters architecture to allow fast iteration and high quality software.
That’s nonsense argument.
Ports and adapters architecture has certain good properties on a specific contexts, but they require training and experience from the team to not create more harm than good by miss applying those patterns blindly and creating unnecessary complexity. Causing more cognitive load on people for simpler use cases that a CRUD model works fine. I don’t even mention onboarding people.
Ports and adapters isn’t a sign of high quality software. You can create Big Ball of Mud with ports and adapters and other architectures for multiple reasons. Quality software is a combination of multiple things, an architectural style doesn’t guarantee quality by itself.
That’s why we have created a microservice per domain
🚩 This sentence shows a low understanding of domain-driven design. A misunderstanding of what a domain is could lead into way to small microservices. How many times you found a microservices with an entity name? User microservice, Product microservice, Payments microservice.
They focus to do their domain responsibility super well, and then we allow others to interact with each one so that we reuse domain logic.
Those aren’t domains but entities, entities that start calling each other and you just created a distributed monolith.
Focus on understanding the domain, its bounded contexts, and its subdomains. Team-sized microservices is a good rule of thumb.
Aleix: Did you consider alternative architectures like leveraging more Spring Boot out of the box features or bigger microservices to avoid all those network calls?
Team: Well, indeed no. In order to become senior developers, we need to show that we know how to do microservices and ports and adapters in an autonomous way. So, part of my performance review objectives was to show that I was able to deliver that core domain alone.
Analysis
There were multiple things that caused microservices purification and ports and adapters everywhere.
People performance review to be senior required to show that they needed to know ports and adapters and microservices.
People are measured by business impact, therefore everyone wants to work on core domains.
Core domains that need to handle high level of complexity, therefore they need to follow the senior best practices.
The reason of all the accidental complexity was based on the wrong incentives. Plus, those incentives were deeply established within the engineering culture.
People expected high level of autonomy within the teams based on those architectural choices, but ignored how change happened within the organization and why they weren’t unable to be fully autonomous.
When exists a separation between the developers and who makes decisions, the architecture will be a reflect of that reality. Yet, because we only see our context, we will apply local maxima solutions that misses the overall context.
Architecture is a signal of what’s happening, but we need to look somewhere else to understand which changes will need to be made to improve.
Direction
We revisit our between teams agreements to optimize for tribe velocity instead of team velocity due to our current nature of work.
We acknowledge that most of our use cases are proxies to an external partner, and we have a very specific use cases that show business complexity advantage. We optimize for this reality.
Coherent Actions
Core team becomes a platform team
The core team will become platform team with a clear purpose of improving the DevEx of integrating with those services by making them more stable and change them less frequently. Instead of big services, we will do a thin platform with well proven and supported use cases.
Removing the name core from the team, allowed us to realize that those services weren’t core subdomains but supportive subdomains from a DDD point of view. Allowing people to change the expectations.
Instead of those services chaining a lot, they needed to be stable and just to a single purpose. Connect with the external provider, and do it in a way that helped others not be exposed to the external provider complexities.
We wanted to reduce cognitive load for the stream-aligned teams consuming from the platform. And in order to do that, we needed them to be sure they can trust the platform.
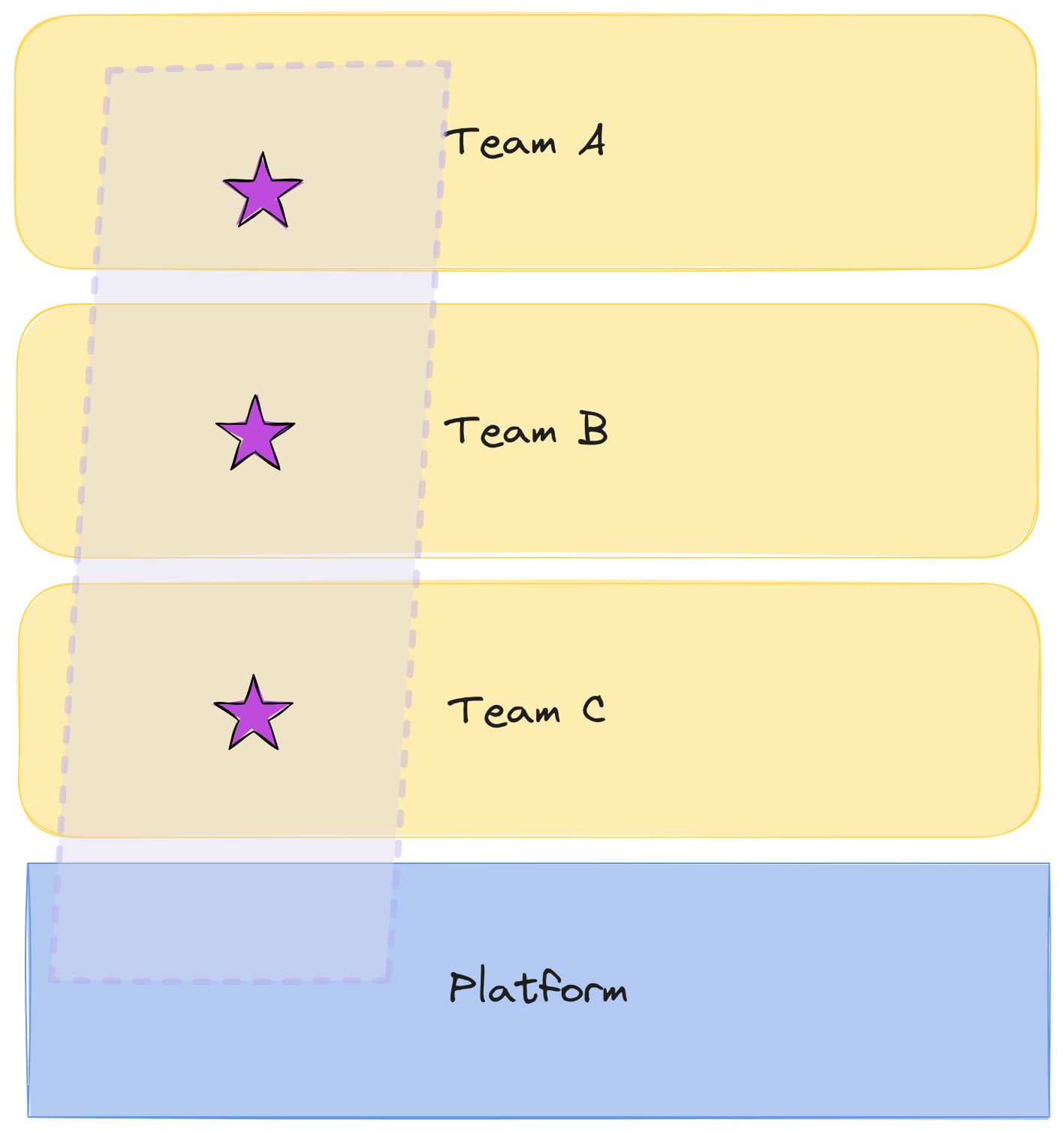
The way we did it was the platform team to collaborate with the steam-aligned teams to understand their needs and create collaboration agreements that would fulfill both parts and improve trust.
Conformist instead of anti-corruption layer for internals
When the platform team understood the team needs. We moved from a fast changing internal platform APIs to stable ones. When the exposed model didn’t change often, we could take advantage of that stability to improve team velocity adopting that external model.
If we ensure backwards compatibility, stability, and other stuff. We can take advantage of that system to give speed to others.
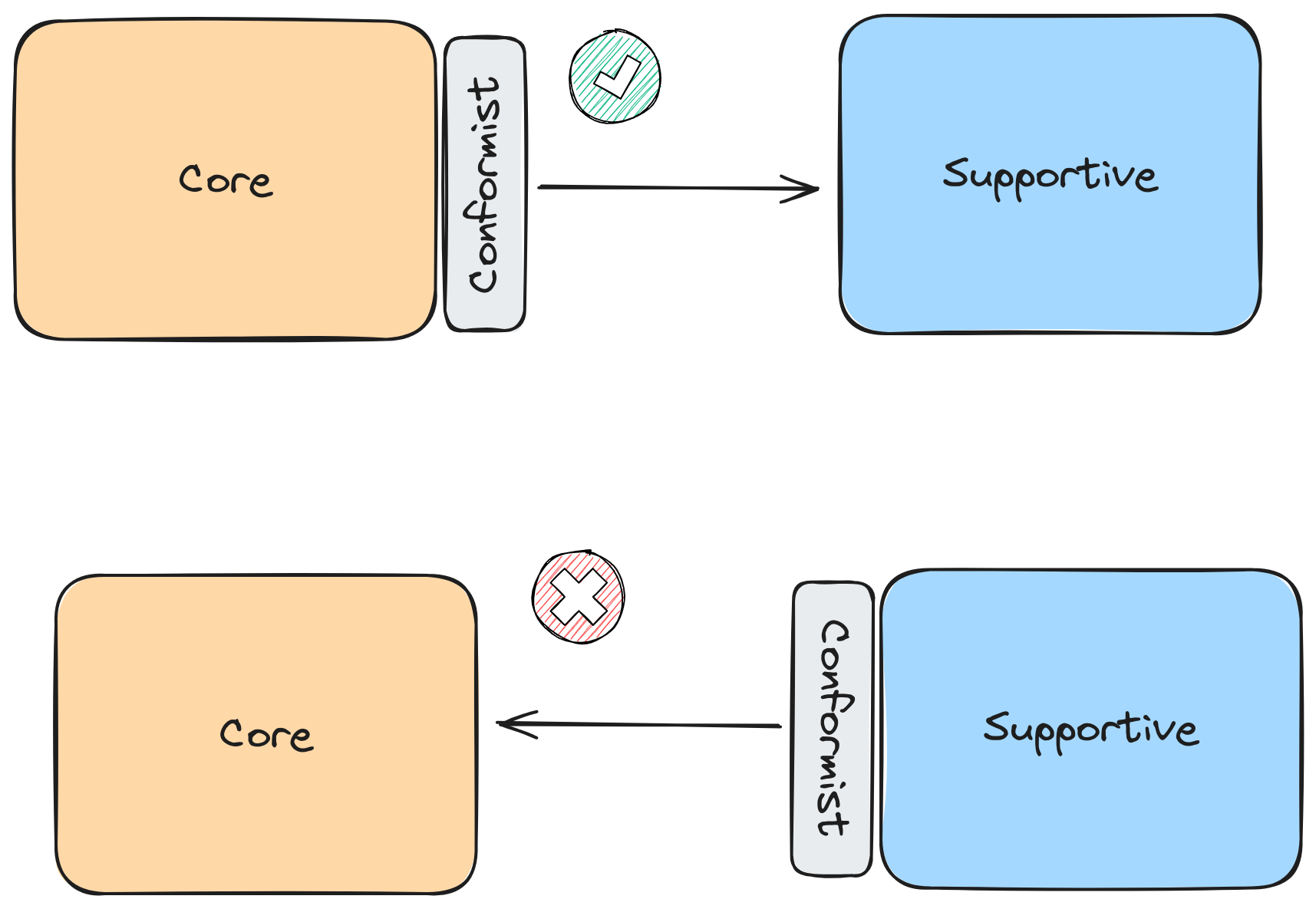
Adopting a conformist approach to a stable system gives teams speed. The opposite isn’t true.
Replace Ktor and Expose with Spring Boot
Ktor had a lot of custom build stuff that were repeating cross services. Adding a new use case was easier in the old way than in the new way.
Introducing Spring Boot helped us to reduce the inertia to the new approach and embracing the coherent actions we were taking forward. It helped us establish, this is how we do it now.
Ports and Adapters provided by Spring Boot with CRUD models and some domain models
We will adopt transactional model in those use cases that aren’t domain rich but network intensive. We will create a rich domain model only on certain use cases.
We will use extensively Spring Boot build in features to improve resiliency and reduce custom build adapters.
By adopting a conformist approach between our customer facing services and platform services, we will reduce the ACL overhead we had.
Most of the internal models looked the same. We had analysed the DTOs at network, entity, and database and they had very minor changes.
We reduced the amount of DTOs between entity and database as they were CRUD models, and we kept the Response and entity parsing to ensure we didn’t break any of the existing API contracts.
So, we started to move away from ports and adapters for the new use cases in favor of MVC+S.
Evolve the senior+ engineer expectations
We stop promoting people only in case they show they can do a microservice with a ports and adapters architecture. That’s no longer an incentive for promotion. Instead, they need to show contextual awareness and aim for the right amount of complexity solution that will allow it to evolve as the business evolves. Evolutionary architecture skills become more relevant than creating complex systems for future (and unknown) business complexity from the beginning.
We did this on the next performance review to not affect the current ongoing expectations. No body wants to be pushing in one direction and the management changes the expectations at last moment and it affects people performance review. This change needed to be done with caution on when to introduce it.
Learnings
Replacing Ktor by Spring Boot and coupling to the framework was our way to materialize the coherent actions we were taking. It was our way to signal to the engineering teams, this is the new way of doing things.
Replacing customized ports and adapters architecture by leveraging Spring Boot components helped people to reduce their cognitive load and learn from the courses available on Internet.
Acknowledge that not all our services were core, helped to reduce the people’s expectations of this needs to be high quality, and what the company says it is quality is ports and adapters and microservices.
Changing how you measure people’s performance is hard and it needs to be taking with care and understanding the people fears and needs.