
Reducing the chaos before addressing the complex socio-technical system
Fintech Engineering Strategy. Post VI

The Fintech post series aims to share my personal experience as an engineer manager and later on as head of engineering, which were the challenges, the decisions, and the good and bad outcomes they had. The content has been adapted to keep the decisions without disclosing internal information.
Fintech Engineering Strategy Post Series
Post II. Building a product vision, and a team, and replacing Ktor with Spring Boot incrementally.
Post VI. Reducing the chaos before addressing the complex socio-technical system [This post]
I introduced the whole context in the previous post. In case you didn’t read it, now it a good moment to do so!


Using the Cynefin Framework and identified that the team was in a chaotic domain, we had to act-sense-respond.
So, how do we move away from the loop of death?

When the teams dynamics aren’t helping but just making it worse?

Making though and focused decisions. One thing at a time.
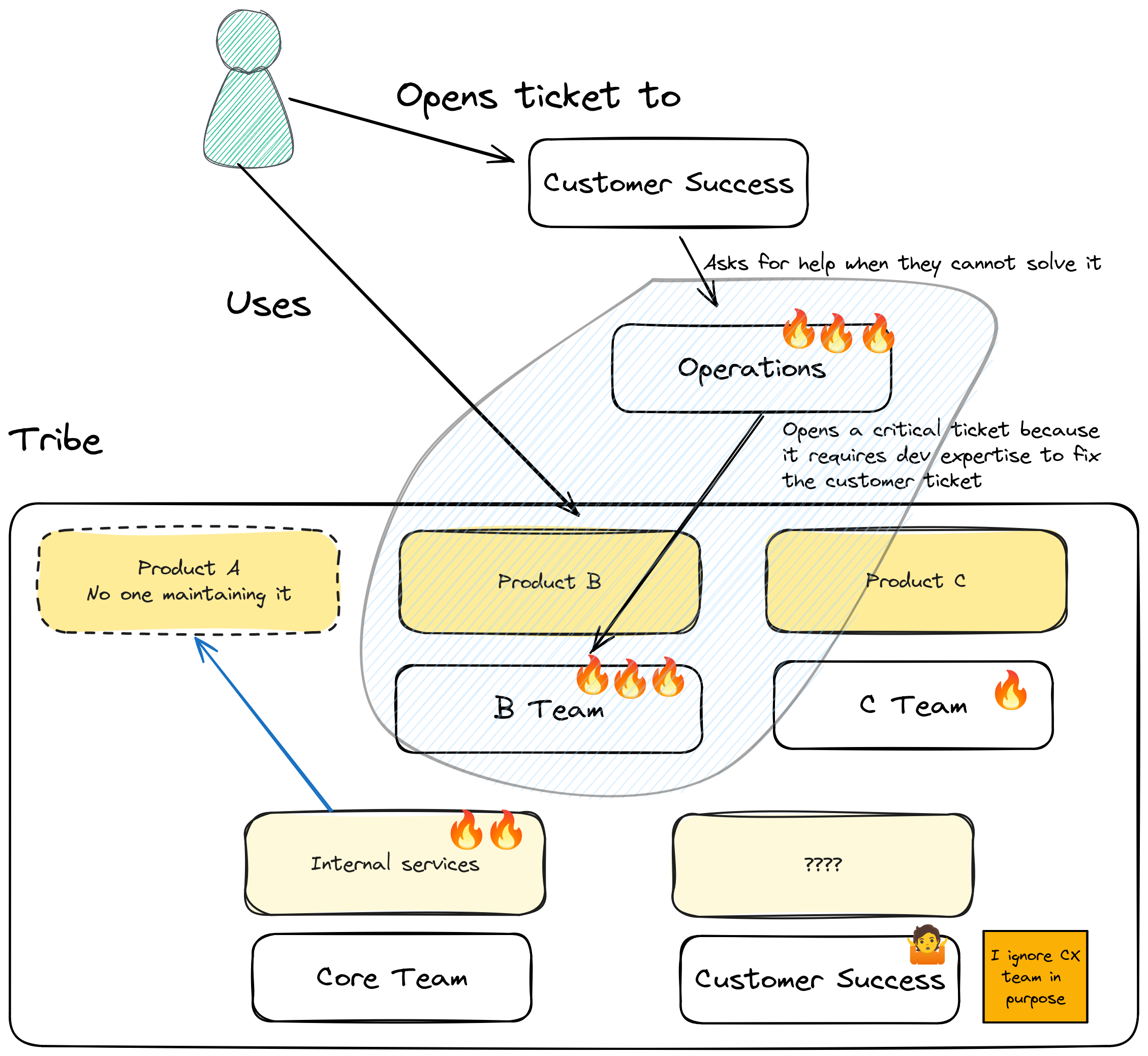
We focused on the area where the chaos is more intense. Operations and B teams.
I could try to align with Customer Success team, but I would had to create a relationship first with the leadership that isn’t part of our tribe, understand their objectives, and align on the purpose.
Too much.
We needed a solution that we could implement ourselves taking advantage of B team domain knowledge.
I joined the team in their day to day supporting activities for customer incident tickets, and I started to pitch the idea that we had to automate that process somehow.
We started with a document listing the steps needed to solve each ticket and we found that:
Several tickets were similar but solved in different ways depending of which microservice or external provider failed.
How to fix the issue was API based most of the time + some checks at database level.
Most of the failure points were outside the team.
Let’s investigate more.
- Aleix: What’s preventing to fix this recurrent problem?
- B Team: This is a responsibility of core team now.(Aleix goes to Core team)
- Aleix: Are you aware of this is happening?
- Core team: Yes, but we have a plenty things to do, we have one person supporting B team on this.
- Aleix: Cool! Did you find already the problem?
- Core team: Yes, it is an external provider that when it fails, it causes multiple of our microservices to become in an inconsistent state. So, we are helping B team to fix those problems manually until our provider fix their problem in their end.
- Aleix: You are also doing manual work? Did you consider make the service more resilient?
- Core team: Yes! We want to, but we don’t have the time to make it, we have a lot to do. Supporting B team, continuing the development of A product, help C team with some of their needs to go to production. We need more people!
- Aleix: I see! Thank you for your time!(Aleix goes to operations)
- Aleix: Could you explain me your process to fix those production issues?
- Ops: Sure! A customer comes to us we don’t know why it is failing to them! and we have a policy that we need to reply within 24h to tell them that we are working on their problem.
- Aleix: Telling them which is the problem?
- Ops: Yes, if we know what’s happening, we can inform them how much it will take to fix the problem and help our customer to be calm because we are working on it.
- Aleix: Is there a difference between letting them know and fixing the problem?
- Ops: Oh yes, we have different SLAs depending on the issue. But because we don’t know, we have to ask the developers to share the information as soon as possible in case it is a critical situation.
- Aleix: And which is the normal case? Are they critical?
- Ops: Oh, no! They are usually problems that could take 3 days to be solved without any problem, we let them know and the customer is happy.
- Aleix: Thank you for your time!
I don’t know if you recall before the all layoffs happened that the norm to fix any problem was to add more people 🤦.
This was our norm too, and you could see that any problem we had, we just added more people. Customer success is unable to keep up with the tickets? Add more people! and so on and so forth.
By adding more people, you change the architecture due to Conway’s Law. And when you change people often, the architecture is a mess because it is unable to adapt at the rate that people do.
That’s was happening to us, a lot. Missing communication everywhere due to the fast growth challenges.
I was able to identify a low hanging fruit. Provide access to the operations teams to understand why a customer had a problem.
If we combine a way to inspect the state of a customer account and a little manual explaining which is the scenario they have, they could inform the customer of their problem without involving the dev team.
Ops team is another product user
A principle we introduced to the B team was “we have at least two users, our end customer and operations team. Our service needs to help both needs”.
By understanding operations team as another user persona, we were able to prioritize work for them from a product perspective. It wasn’t anymore a dev thing, but a Product-Eng thing. Product become aware of the operations needs, and we started to include them in our quarterly prioritization.
So, what we need to do?
The company had several internal dashboards in place which they required to talk with those teams because they weren’t self served. You need to talk with the team, share your needs, prioritize the dashboard to our product integration, and … too much time. Yet another collaboration!
We know that collaboration isn’t allowing fast flow, so, an alternative?
Let’s build a dashboard ourselves. Should it be pretty? No. Should it be secure? Yes. Should it do much? No. Is it aligned with the company principles? No, because we were building something that we shouldn’t do in the first place.
Internal crappy dashboard that kind of works
And that’s what we did! An internal crappy dashboard with Vue via CDN to take advantage of the existing APIs to show data to the operations team secured.
What did it do?
You add the customer ID, and it shows you its state. You go to our internal wiki page and you know how to reply to the customer.
At this point, the amount of tickets dropped in criticality. We no longer had to solve them in the same day. Now we had time between the ticket was open and we had to resolve it.
We got some air!
Automating devs knowledge
- Aleix: Should we consider automating what you shared in the Wiki page at the Product B?
- B team: Well, we shouldn’t have to do this here… but it is true that we are suffering a lot.
- Aleix: What’s the problem of adding the logic here?
- B team: Is it duplication? Shouldn’t it go into the other services?
- Aleix: Yes, it is.
- B team: Isn’t it bad?
- Aleix: Well, it is the place that will take us less time to build, the other implies communication and collaboration with other teams. I think the effort is higher than just do it here.
- B team: I think it will just make our code worse.
- Aleix: Probably yes, it will feel wrong until we learn more about the problem. We shouldn’t touch the logic that’s serving our customers, but build it aside. Ready to be deleted at some point, even though that point might never happen because it is outside our team responsibilities. I’m taking care of this, but it will take longer than we would like to.
- B team: OK, we can start this way and see how it evolves.
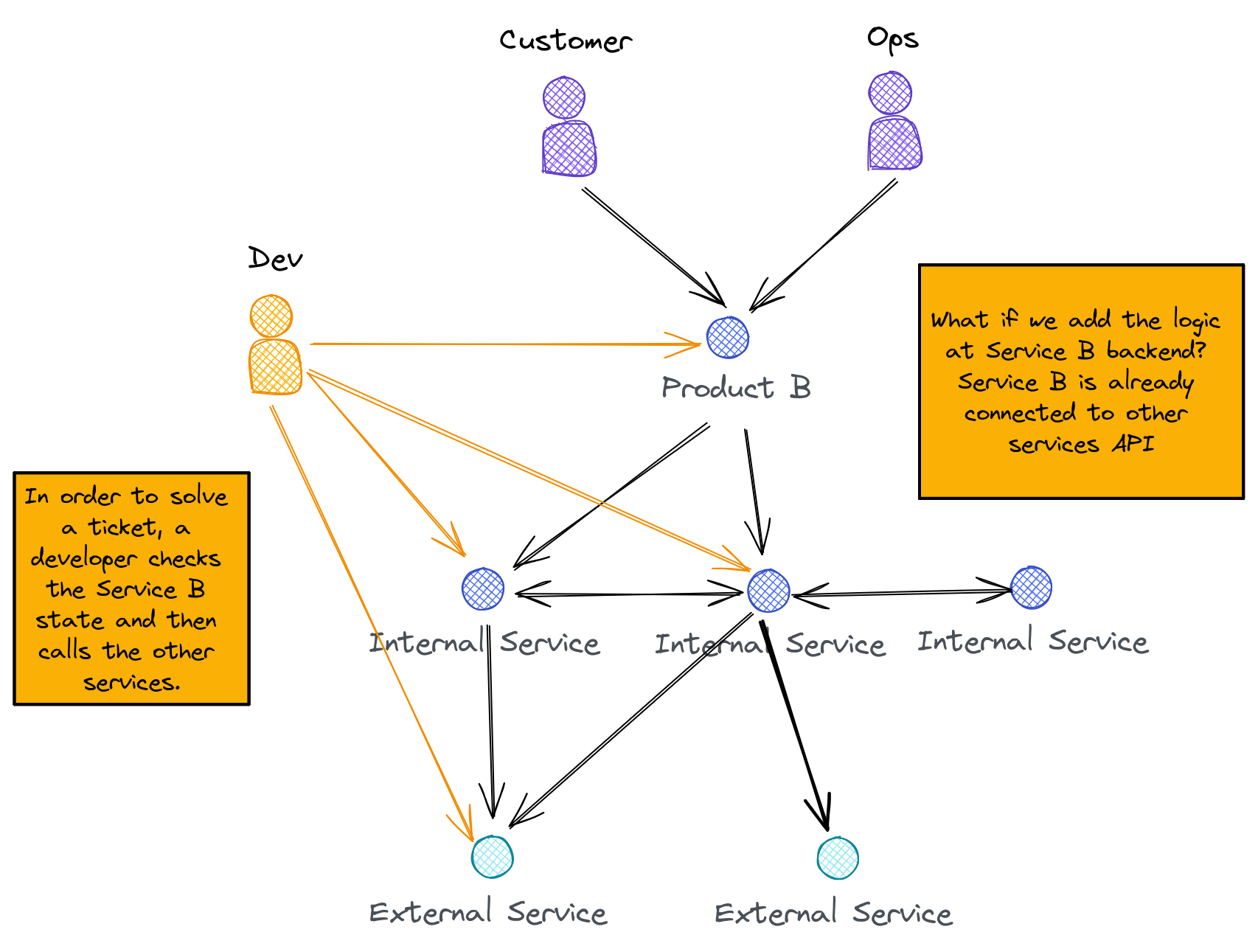
And that’s how Service B become aware of all the other services problems, but made the product resilient for the customer perspective.
The team had a very interesting idea, let’s create self-healing system by implementing the rules to help the system to reach a coherent state.
But we had a problem, not all the scenarios can be automated. Some requires opening a ticket to our provider support center.
What did we do? Implement the idea in small increments.
The dashboard starts the automation
Instead of a developer calling the REST API directly, we added specific pages into the dashboard to start the most common operations the devs team made, and now they were available for the operations team to do autonomously.
So now, instead of opening Postman, we opened a dashboard with a list of operations we could use for each scenario that our end customers needed support with.
At first, operations didn’t do it by themselves, and it is normal! If you need to support several customers each day, it is not the same opening tickets and a team of at least 2 developers supporting, than do it yourself.
We had to do several meetings, looms, improve our documentation, and improve the dashboard to make it more accessible for the ops team.
We were able to convince them to support the customers directly because we needed to free the developers for that operations work so they could fix the system.
The service self-heals
Lucky us, we got into the point where 2 developers weren’t spending their time to support end customers directly and start implementing the service improvements to make it more resilient.
The team implemented a nice state machine that could self-heal on the scenarios that were automatizable, and let us know via a Slack notification when it wasn’t possible.
Reaching this point was tedious, demanding, energy taking, and demotivating.
But when you reach the point that you can sustain the product, the issues in production that affect end customers drop to almost 0, it is a huge energy and moral boost.
You know you did a good job! And it was a multi-team effort to accomplish it. We celebrated this moment a lot.
Afterwards learnings
If I had to highlight some actions that helped us to move away from the chaotic situation, they are:
Focusing on what you can control within the team to avoid team collaboration in a chaotic situation. You increase the chaos by involving people. Be sure you need to involve the people yes or yes before doing so.
Instead of aligning with multiple people about team responsibilities, I took the decision to make it at team level by de-prioritizing a lot of the planned product work in favor of stabilizing the system. I made that work as part of product work and multiple blockers were removed. I had a good and strong relationship with the PM of the B team, and this was key to have a common speech of why we were making those decisions.
Instead of following the internal approach to building dashboards (which they weren’t self served, and the DevEx wasn’t good enough), we started a crappy Dashboard that did the job. Fixing customer problems > make it good at the first try.
By providing the dashboard for the operations people, we learned more about our domain and customer needs. By understanding and supporting the customer, we were capable of implement the right level of self-healing mechanisms later. Otherwise, we could had miss-implemented some of the use cases because we missed deeper domain knowledge. Because how a system failed is also part of the domain knowledge due to several regulatory specific policies.
Going fast on making the decisions and implementing the good enough increment to free up developers was essential.
I had to adopt a command and control leadership style to make the situation stable, and it helped everyone to focus on the bet.
On a chaotic context, the important aspect is acting and moving away from it, that’s why this leadership style made sense. You can see more about adaptative leadership styles here.

Product teams thinking of operations as a user persona impacted how we understood the teams responsibilities
After leadership noted that a product team by itself was providing good support to customers via operations team, they questioned why we needed a specific CX team to build those dashboard in the first place.
This approach become part of how we were doing things from now and on.
The outcome of the strategy becomes culture

On this post, I use the term “Strategy” as what Richard Rumelt's defined on his book "Good Strategy / Bad Strategy".
Moving into the next big thing, how did we end up in this situation in the first place?
Then, it was time to tackle the next big thing. The tribe.
What’s happening at a tribe level that our socio-technical systems is that fragile? Which dynamics do we have that causes this situation over and over again?
It looked like the there was no root cause, but a set of things that were interrelated that caused the system to behave the way it was doing it.
In the next post I will go in depth on how I analyzed a complex socio-technical system and which bets I took and why.
Thank you for reading!