
A team grouping (tribe) with local optimization thinking. Making sense of complex socio-technical system
Fintech Engineering Strategy. Post VII

The Fintech post series aims to share my personal experience as an engineer manager and later on as head of engineering, which were the challenges, the decisions, and the good and bad outcomes they had. The content has been adapted to keep the decisions without disclosing internal information.
Fintech Engineering Strategy Post Series
Post II. Building a product vision, and a team, and replacing Ktor with Spring Boot incrementally.
Post VI. Reducing the chaos before addressing the complex socio-technical system
Post VII. A team grouping (tribe) with local optimization thinking. Making sense of complex socio-technical system. [This post]
If you didn’t read the previous posts yet, I suggest you to because it is a continuation and I assume you have all the context. Check it here:

Moving into the next big thing, how did we end up in this situation in the first place?
Then, it was time to tackle the next big thing. The tribe.
What’s happening at a tribe level that our socio-technical systems is that fragile? Which dynamics do we have that causes this situation over and over again?
It looked like the there was no root cause, but a set of things that were interrelated that caused the system to behave the way it was doing it.

How did we start tackling the complexity? How did we find some signals to tell us what was goining on? Well, it was a mix of things.
I considered that focusing on the social interactions, responsibilities, and employee experience could give us some good insights.
I’m gonna explain here how we combined Team Topologies, Context Mapping, Team Cognitive Load, Core-Domain Chart, and Wardley Mapping to uncover where to do a set of micro interventions to the socio-technical system.
As an outcome of the workshops we did, we came up with this way of describing the architecture that shown business purpose inspired on DDD Subdomain types.

So, let’s start with the engineering strategy that I’m so proud of that I was able to do with a very talented people. It contains:
A great implementation of a Platform as a Product approach based on Team Topologies.
How we measured Team Cognitive Load to bring focus and direction.
Investing in moving non-competitive services to supporting subdomains.
How a set leadership decisions created success for some teams but created a huge inertia on others to adopt the new approach.
Engineering Strategy
Purpose
We weren’t able to have a sustainable flow of change. Every now and then we had some kind of a crisis that required that kind of hero culture to fix the stuff.
We weren’t a reliable tribe. Even though at team level we improved.
Our goal was to make the tribe reliable/resilient and create sustainable flow of change to support the different business initiatives.
We were able to put into production one product of three. So, how do we accomplish:
Keep improving Product B based on customer feedback and needs.
Release Product A and C.
Context
As a tribe, we were much exposed to external changes (either higher leadership, other tribe needs, competition moves, or just regulatory changes) that required fast interventions, which usually implied a leadership top-down decision.
Interestingly, I found that even though some teams might be performing at a maturer level, it doesn’t translate directly into a tribe being more mature.
We didn’t have a predictable roadmap, and we were much jumping on what product/business/sales/leadership said it was more important that week.
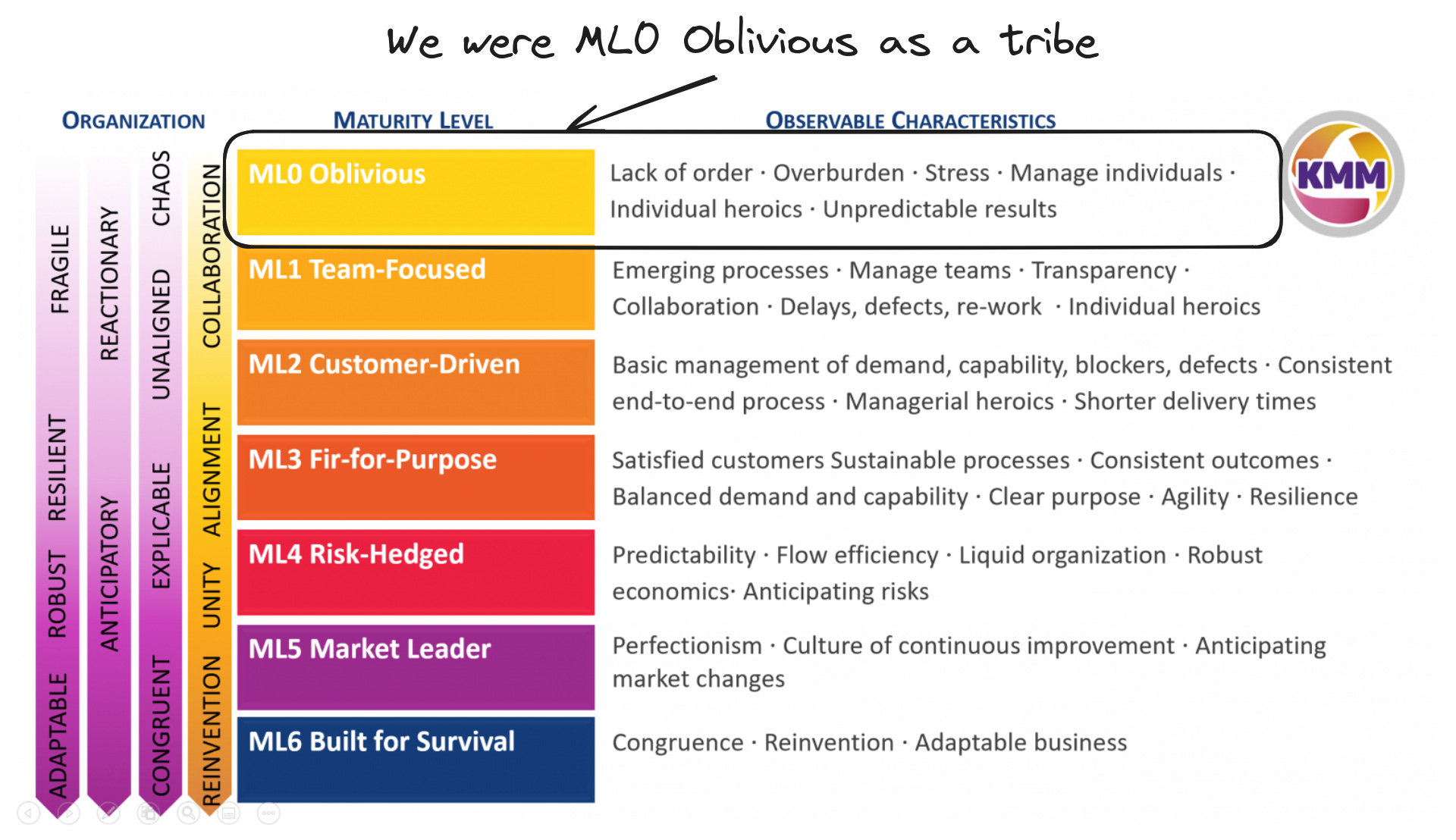
As middle-leadership team at tribe level, we were overburden, stressed, too involved in the teams day to day to understand what was happening, and we were requiring staff engineers to coordinate tribe level initiatives and firefight all the time.
Stuff was more calm for some teams because they accomplished E2E ownership (remember B team just was supporting end customers and operations team, and they had a easier time now), but when it come to collaborating with other teams within the tribe, we had a lot of back and forth because backlogs were full and supported multiple stakeholders.
As leadership of the tribe, we noticed that change happened from multiple places and it didn’t take into account how we organized the tribe. When some stakeholder needed a change, they were able to talk directly to some PMs to see if they had backlog capacity to deliver a feature, regardless if it was from their teams ownership.
Understanding
When I face a complex socio-technical system, I know that there is no root cause that explains what is happening. So, I would rather find the area that we could impact the most because chaning anything will require a high effort.
I also know that the purpose of a system is what it does, which we had to modify to create the results that we wanted. It meant we needed to change how people worked together with the hope that it will translate into a better situation.
I focused on understanding the next areas:
How change happen.
Team Cognitive Load.
Teams interactions.
with the hope that we could find the right place to introduce change incrementally.
How change happen
I sat down with the VP of Business to understand better the business model, and from there I continued to understand how an initative was created, how it materializes, and it ends on different teams.
The first realization is that the initative and how the teams were structured didn’t match.

For the business, we were a single product, for us, we were three different produts.
🤯 Of course all this chaos!
At somepoint, we evolved from being a single product/team, into different teams and products because the complexity was that high that a single team was unable to deliver all the expectations.
The tribe evolved, but how the business understood the product didn’t.
Remember the architecture? Everything depending and talking to everything else?
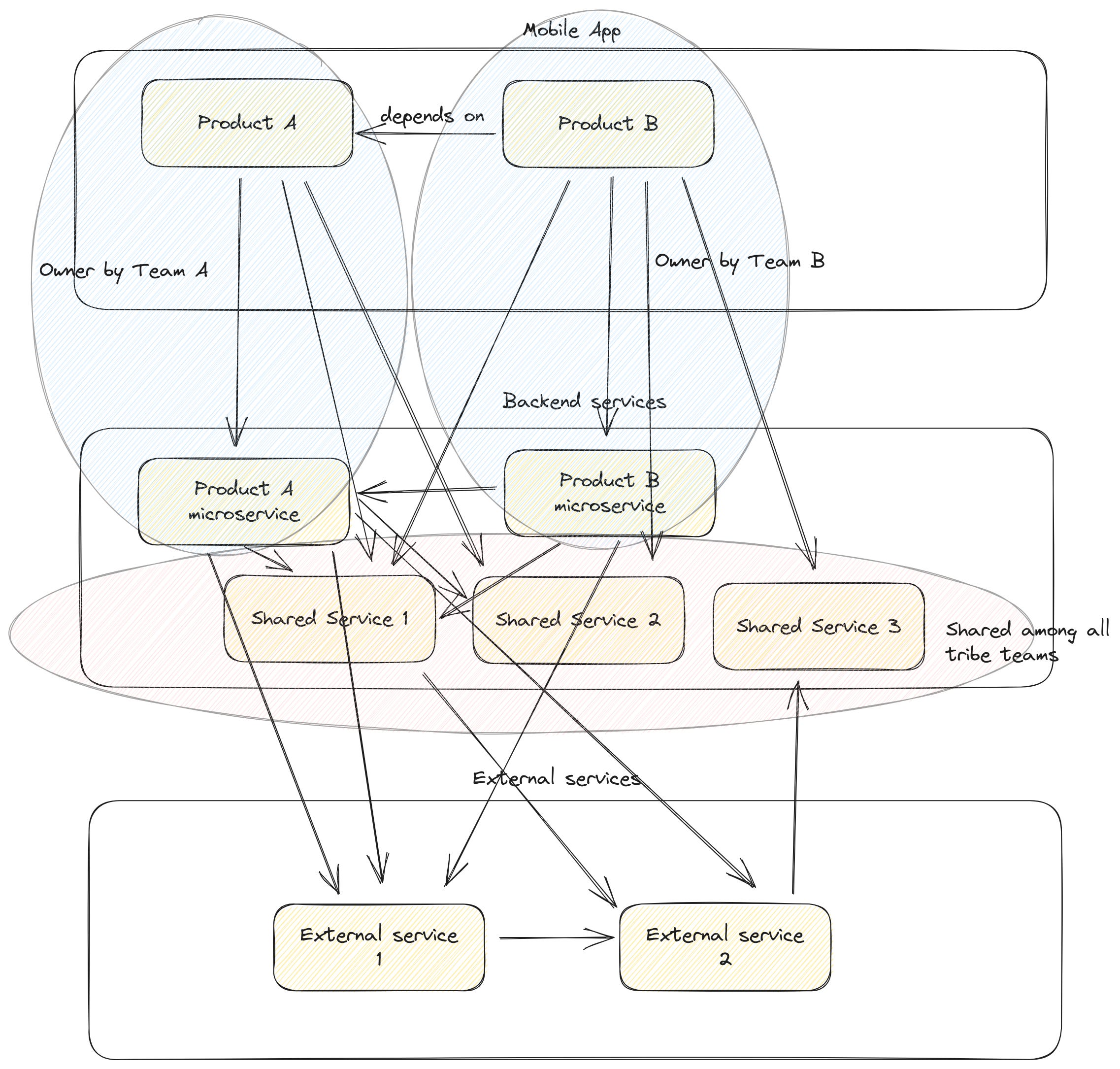
Now it makes sense! It is how the business understand the domain and how the different initiatives are funded.
When you are a scale-up, with people rotation, with leadership rotation, and so on, it is normal that this memo got lost, and more in a company that relies a lot on spoken communication instead of writing communication. If a key people left, a lot of context is lost.
I’m sure this was known by someone but I didn’t speak with that person, or that person wasn’t there anymore.
I wrote that down as part of the engineering strategy we were designing.
Even though it was an interesting data point, I didn’t consider that we should start by changing how the whole organization understood our tribe/product. It involves too many people from different layers.
I was sure that we were able to find another point to start introducing change at a smaller scale.
Architecture that shows business purpose
We identified that how the business understood the domain/product and us wasn’t the same. Now, we wanted to understand two things:
If how we understood the problem and the architecture was the same.
Untangle the use cases that touched multiple product/services.
When we know that a user request translates into multiple API calls, we have a potential distributed monolith.
This is the first picture of our architecture that we created.
It provided good insights.
Everything we do is core.
Everything else is either supportive (when we run in our cloud) or generic (when we consume it as a SaaS for example).
It shown the use cases!
We could see and E2E use case and how it navigated all the infrastructure. We didn’t have traces or any observability tool to tell us that, so we had to rely on people knowledge to build it.
By asking for the architecture, it brought interesting conversations of why things were failing.
We should do Event-Driven Architecture. We should decouple here and there. Let’s do micro-frontends.
People had opinions, and they were founded in their day to day pain. But the problem wasn’t in the architecture per se, but how we interacted with each other, how we introduced change, and so on that caused this problem.
I knew that if we stopped analysing there, a huge refactor or technology migration would happen but it wouldn’t fix our problems.
Team Cognitive Load
People had pain and they were motivated to help reduce it. But which was their real pain? Should we listen to the loudest voices? Are we missing something? Is it a local problem or a tribe level problem? What should we fix first?
Thanks to the retrospectives, we had some data points on what was painful for teams, but each team had their own roadmap and it was hard to create a coordinated initiative.
Is there something that affects all the teams?
We wanted to provide some clarity on what was causing a bad developer experience that could help us to identify a shared problem cross teams.
We used the Team Cognitive Load Assessment survey by Team Topologies, and we adapted it to our context. We didn’t have a tool like Teamperature back then, so it required a manual work for us, the leadership team.
What the Team Cognitive Load Assessment told us was:
Building, testing, and deploying services was great.
Understanding the business needs was ok.
Operating the services was a mess.
Ugh! The conversations were about changing the architecture to improve reliability, but the real problem is that we didn’t have the right observability and monitoring tools in place.
We were paying SaaS observability tool and self-hosted Elastic Search with Kibana… So… let’s dig here.
We asked people how they were able to understand what was going wrong in the system.
- Devs: We use CloudWatch to see the logs, and then we go to the database to see why it is in the wrong state.
- Aleix: For all the services?
- Devs: Yes.
- Aleix: Why you don’t use SaaS observability tool or Kibana for this?
- Devs: SaaS observability tool is hard, we don’t know how to use it. And Kibana doesn’t work.
- Aleix: And when a problem happens with multiple systems?
- Dev: We ask the Staff Eng.(Aleix goes to talk to the Staff Eng)
- Aleix: Hey! Are you aware of this problem?
- Staff Eng: Yes… we know but we don’t have time for training. The tool was decided by the global platform team but there was never a training.(Aleix goes to the global platform team)
- Aleix: Hey! Are you aware of this problem?
- Platform dev: Yes, but we are now migrating to another tool because our SaaS observability tool isn’t working.
- Aleix: but the problem is training, why not investing the migration time into training people?
- Platform devs: That’s not our focus now, we expect teams to learn the tool. And the new tool has a good learning materials for free
The problem seems quite obvious, but I guarantee you that it is more common than you might expect. Choose a tool, do not train people on it, blame the tool, change the tool, don’t train people, repeat.
We identified a skill gap.
Team Interactions
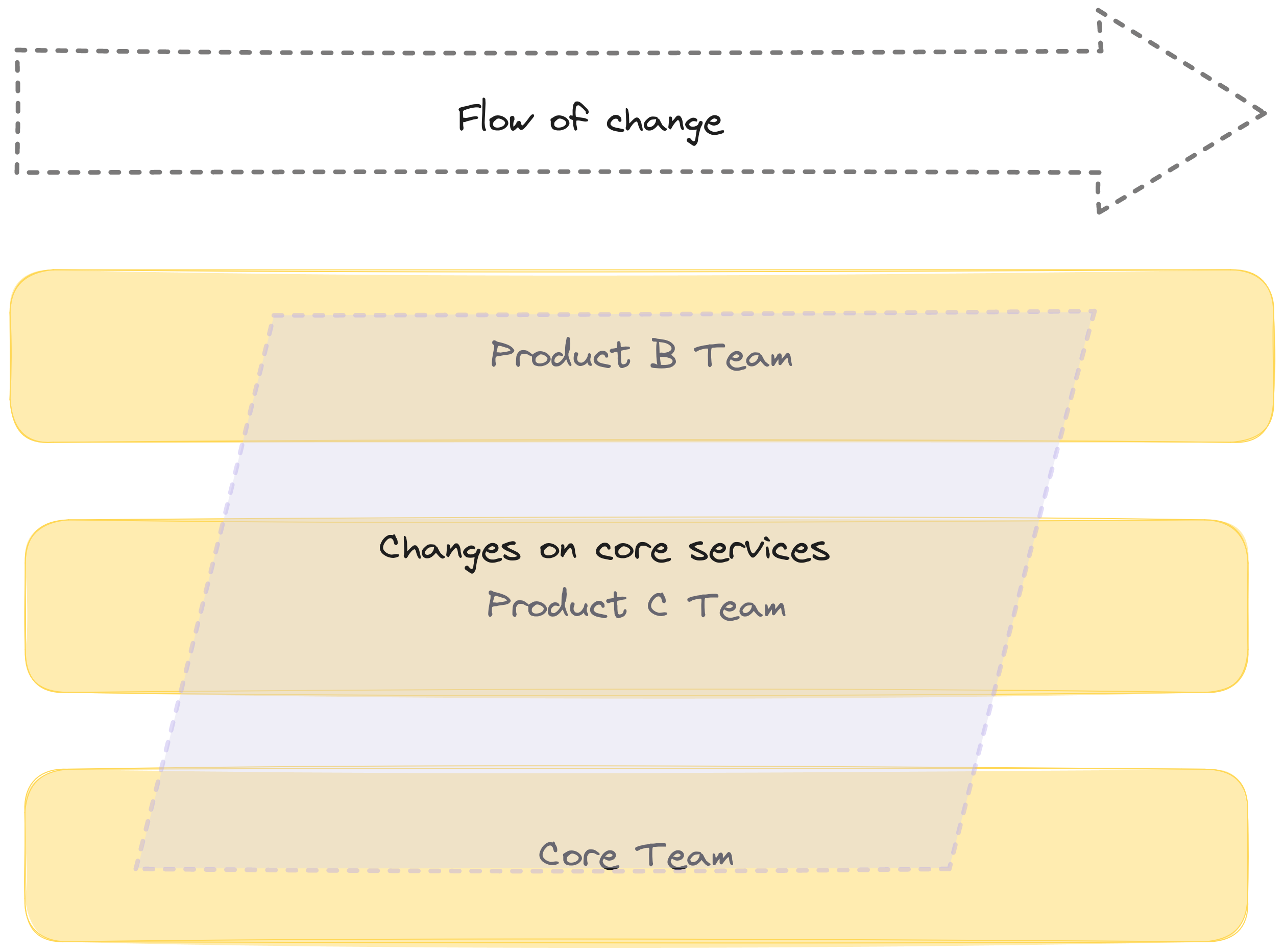
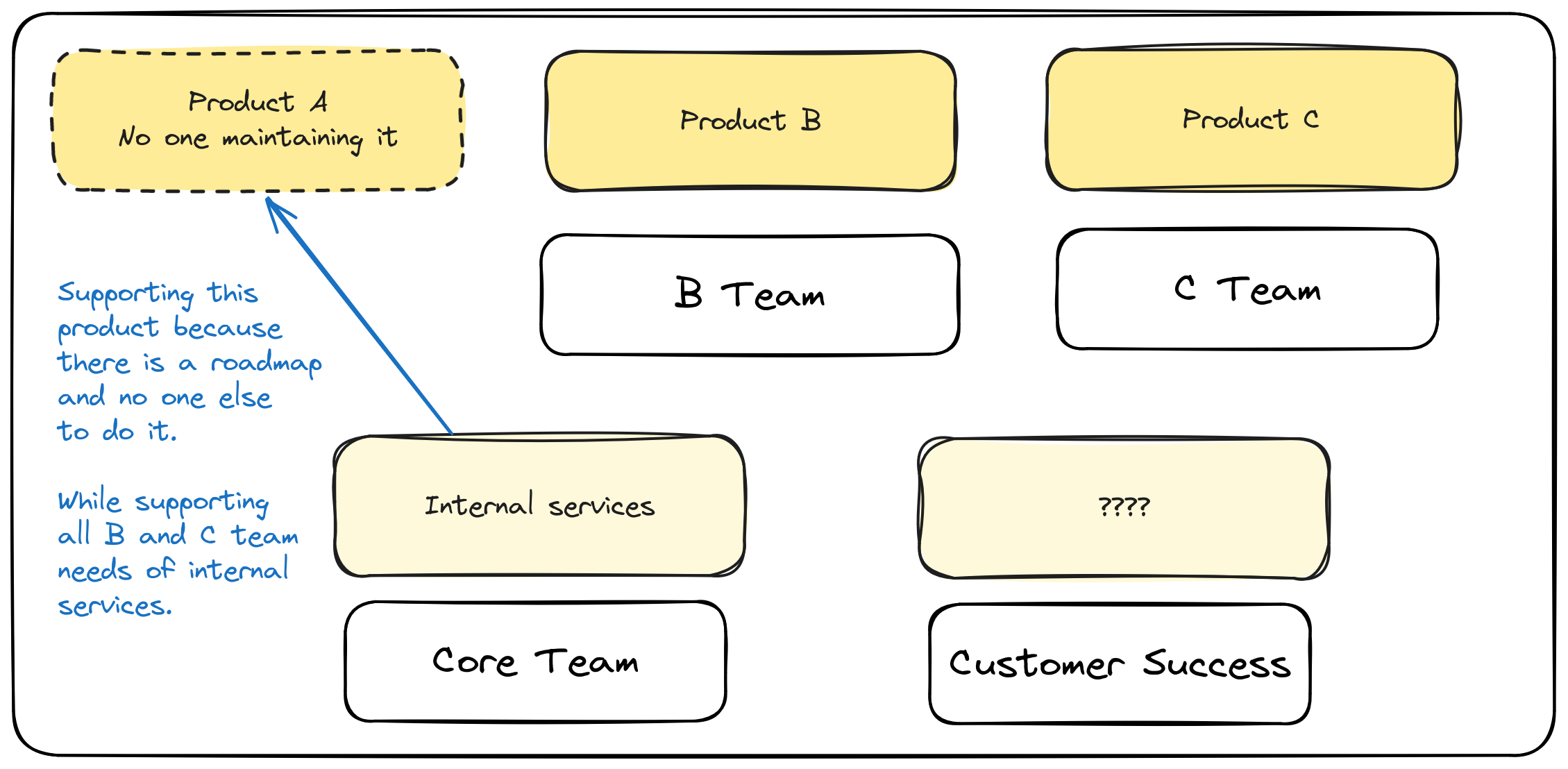
By intoducing the Core Team, we also introduced the collaboration between all the teams when anything required a change to the core services.
The Core Team was doing two things:
Delivering the Product A because no one else was there to do.
Introducing change on the shared services.
Here I leave an example of how a Stream Aligned could evolve into Platform Team, but it wasn’t how it happened to us.

Enough to start the direction
At this point, I considered that we understood enough about our context and situation at hand. We could start making some hard decisions on how to proceed.
I will go in depth on the next post.